CM3leon:テキストと画像生成の新たな可能性
CM3leon はテキストと画像の生成において画期的なモデルです。このモデルは単一の基盤モデルとして、テキストから画像へ、画像からテキストへの生成を両方実現します。
オーバービュー: 最近の数ヶ月間、自然言語処理の進歩とテキスト入力に基づいて画像を生成できるシステムのおかげで、生成型 AI モデルに対する関心と研究が加速しています。CM3leon はこの流れの中で誕生したモデルで、テキスト専用の言語モデルから適応されたレシピで訓練されています。
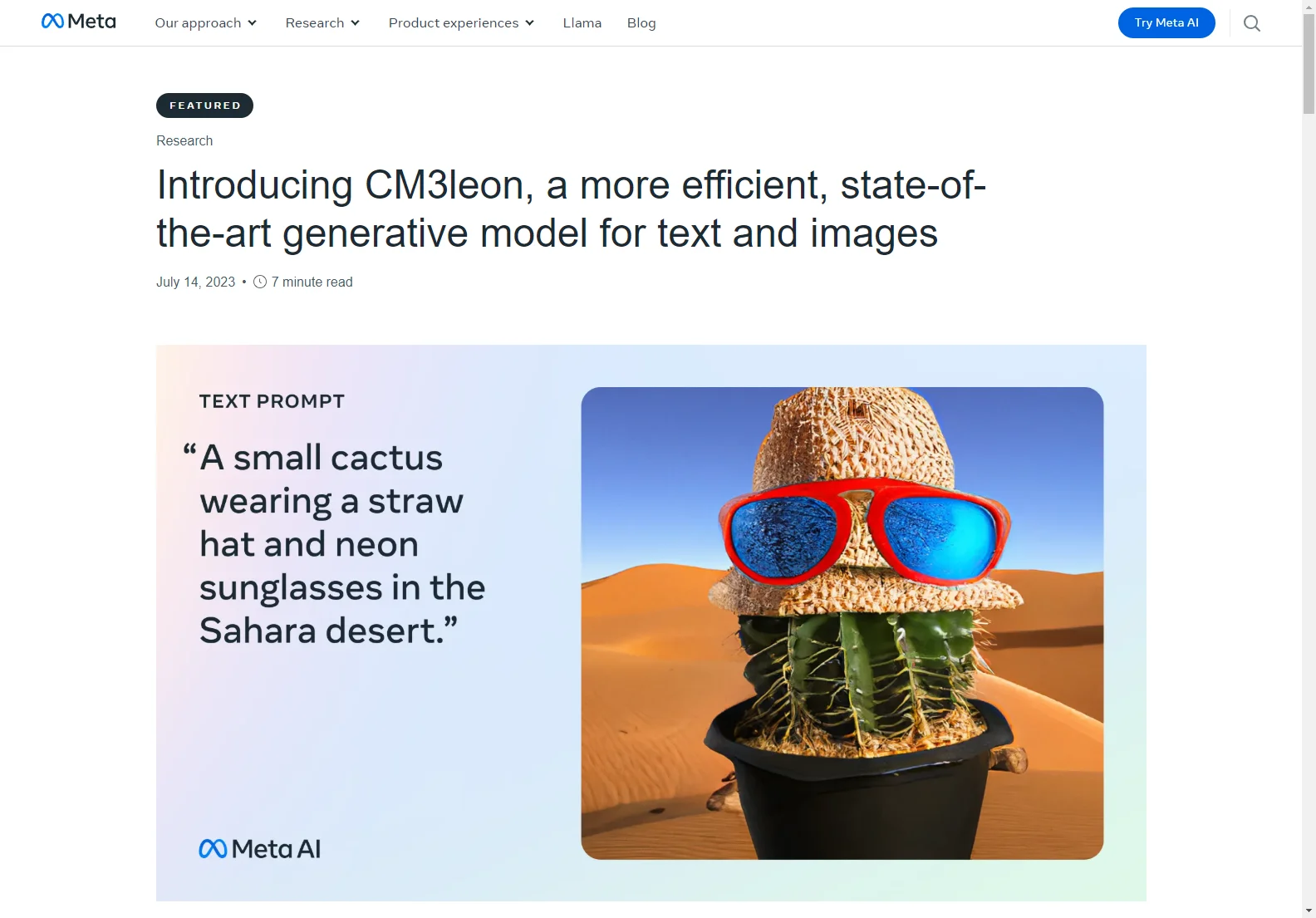
コア機能: CM3leon は大規模な検索拡張事前訓練ステージとマルチタスクの監督微調整(SFT)ステージを経て、強力なモデルを作り上げています。このモデルはテキストから画像への生成において最先端の性能を達成しており、以前のトランスフォーマーベースの方法よりも5倍少ない計算量で訓練されています。また、このモデルはオートレグレッシブモデルの多様性と効果性を備えながら、低い訓練コストと推論効率を維持しています。
基本的な使用方法: CM3leon は様々なビジョン言語タスクにおいて高いパフォーマンスを発揮しています。例えば、テキストによる画像生成や編集、画像のキャプション生成、視覚的な質問応答、テキストベースの編集、条件付き画像生成などが可能です。また、構造に基づいた画像編集やオブジェクトから画像への生成、セグメンテーションから画像への生成なども行うことができます。
CM3leon の登場は、生成型 AI モデルの発展において重要な一歩となり、高忠実度の画像生成と理解の可能性を広げています。