ELECTRA: 効率的な言語モデル
ELECTRA は自然言語処理の分野で画期的な存在です。近年の言語プレトレーニングの進歩により、BERT、RoBERTa、XLNet、ALBERT、T5 などの最先端モデルが登場しましたが、ELECTRA はそれらとは異なるアプローチを採用しています。
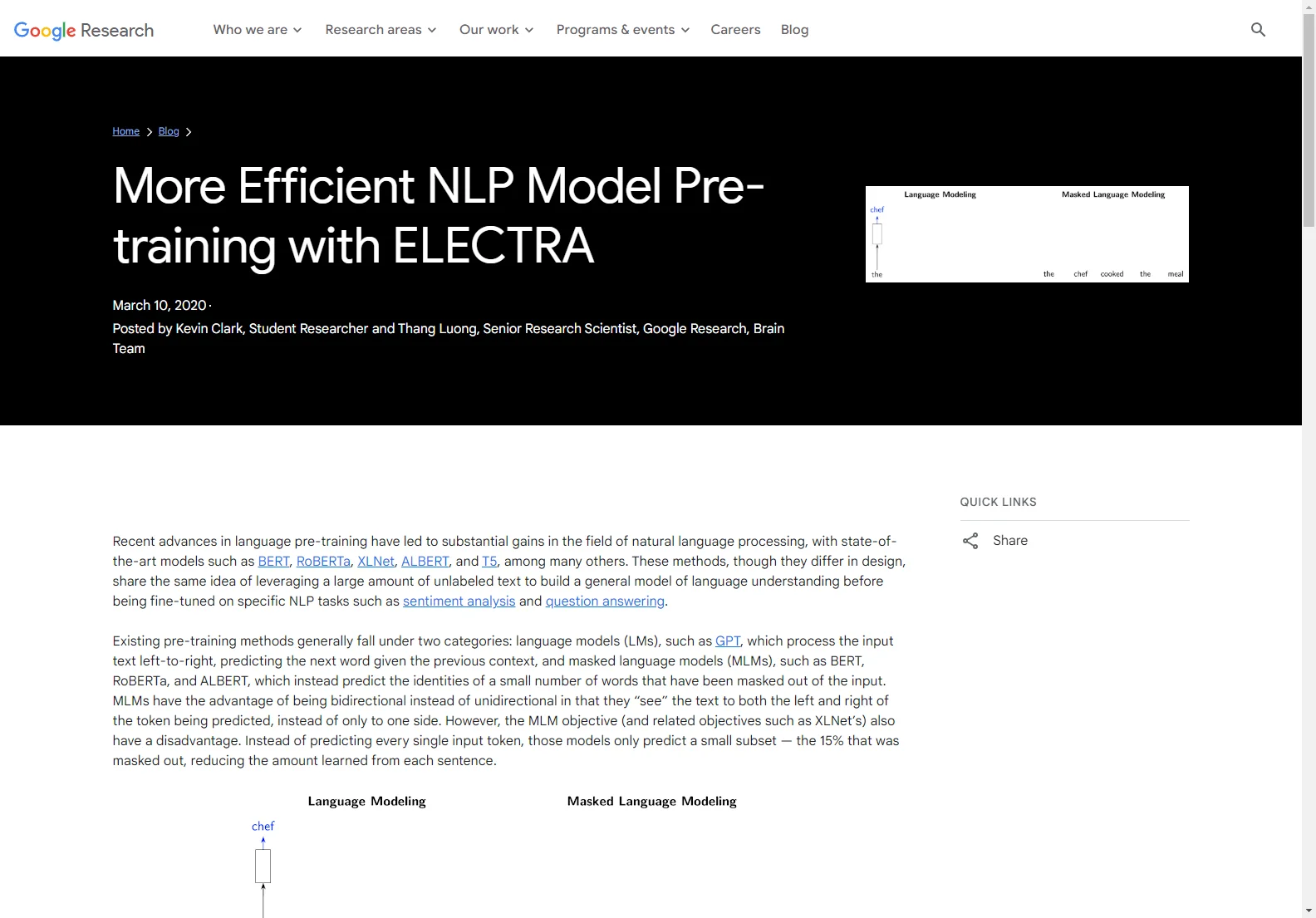
概要:既存のプレトレーニング方法には言語モデル(LM)とマスクド言語モデル(MLM)がありますが、それぞれには利点と欠点があります。ELECTRA はこれらの欠点を克服するために、新しいプレトレーニングタスクである「置換トークン検出(RTD)」を使用します。
コア機能:RTD は双方向モデルを訓練しながら、すべての入力位置から学習します。入力を破壊するために、一部の入力トークンを誤ったがある程度妥当なものに置き換え、モデルは元の入力のどのトークンが置き換えられたかを判断する必要があります。このバイナリ分類タスクはすべての入力トークンに適用されるため、MLM よりも効率的です。
基本的な使用方法:ELECTRA は TensorFlow 上でオープンソースモデルとしてリリースされており、テキスト分類、質問応答、シーケンスタグ付けなどの下流タスクでの微調整が可能です。現在は英語のみですが、将来的に多言語でのプレトレーニングモデルのリリースが期待されています。