Phenaki: Revolutionizing Video Generation
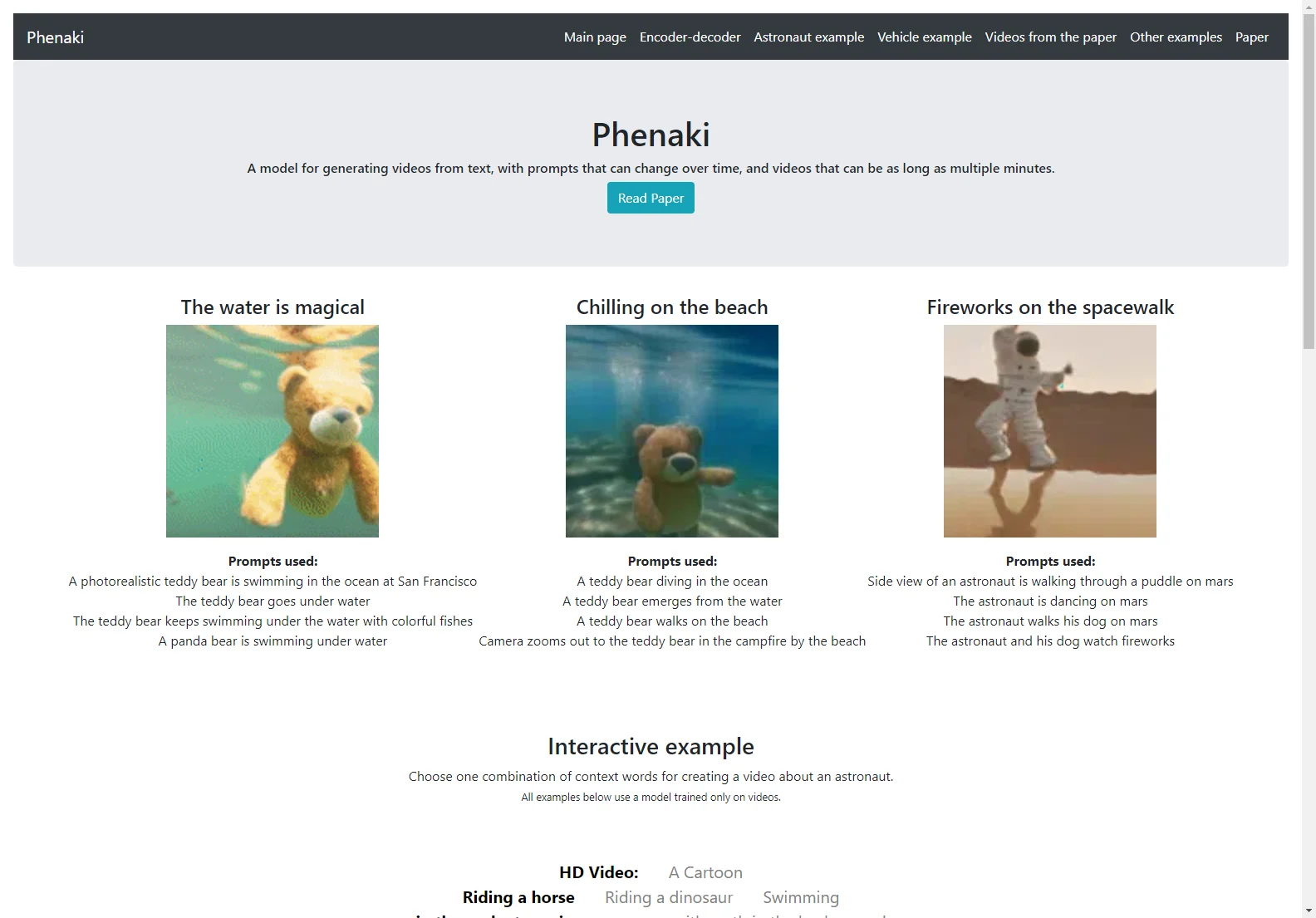
Phenaki is a remarkable model that has the ability to generate realistic videos based on a sequence of textual prompts. This cutting-edge technology addresses the challenges associated with video synthesis from text, such as computational cost and limited data.
The model introduces a new causal model for learning video representation. It compresses the video into a small representation of discrete tokens using causal attention in time, enabling it to handle variable-length videos. To generate video tokens from text, a bidirectional masked transformer conditioned on pre-computed text tokens is employed. These generated video tokens are then de-tokenized to create the actual video.
In terms of data, Phenaki demonstrates how joint training on a large corpus of image-text pairs and a smaller number of video-text examples can lead to generalization beyond the available video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos based on a sequence of prompts in the open domain.
Phenaki's proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video. This makes it a significant advancement in the field of video generation.
Overall, Phenaki opens up new possibilities in the world of video content creation, offering a powerful tool for generating engaging and realistic videos from text prompts.