ALBERT: Revolutionizing Self-Supervised Language Learning
ALBERT is a significant advancement in the field of natural language processing (NLP). It builds upon the success of BERT and takes the state-of-the-art performance to new heights. This open-source implementation on TensorFlow offers a number of ready-to-use pre-trained language representation models.
One of the key features of ALBERT is its efficient allocation of the model's capacity. By factorizing the embedding parametrization, it achieves an 80% reduction in the parameters of the projection block with only a minor drop in performance. Input-level embeddings learn context-independent representations, while hidden-layer embeddings refine them into context-dependent ones.
Another critical design decision is the elimination of redundancy through parameter-sharing across layers. This approach slightly reduces accuracy but results in a more compact model size. Implementing these two design changes together yields an ALBERT-base model with a significant parameter reduction while still maintaining respectable performance.
The ALBERT-xxlarge configuration demonstrates the potential of scaling up the model. With a larger hidden-size, it achieves both a parameter reduction and significant performance gains. This shows that accurate language understanding depends on developing robust, high-capacity contextual representations.
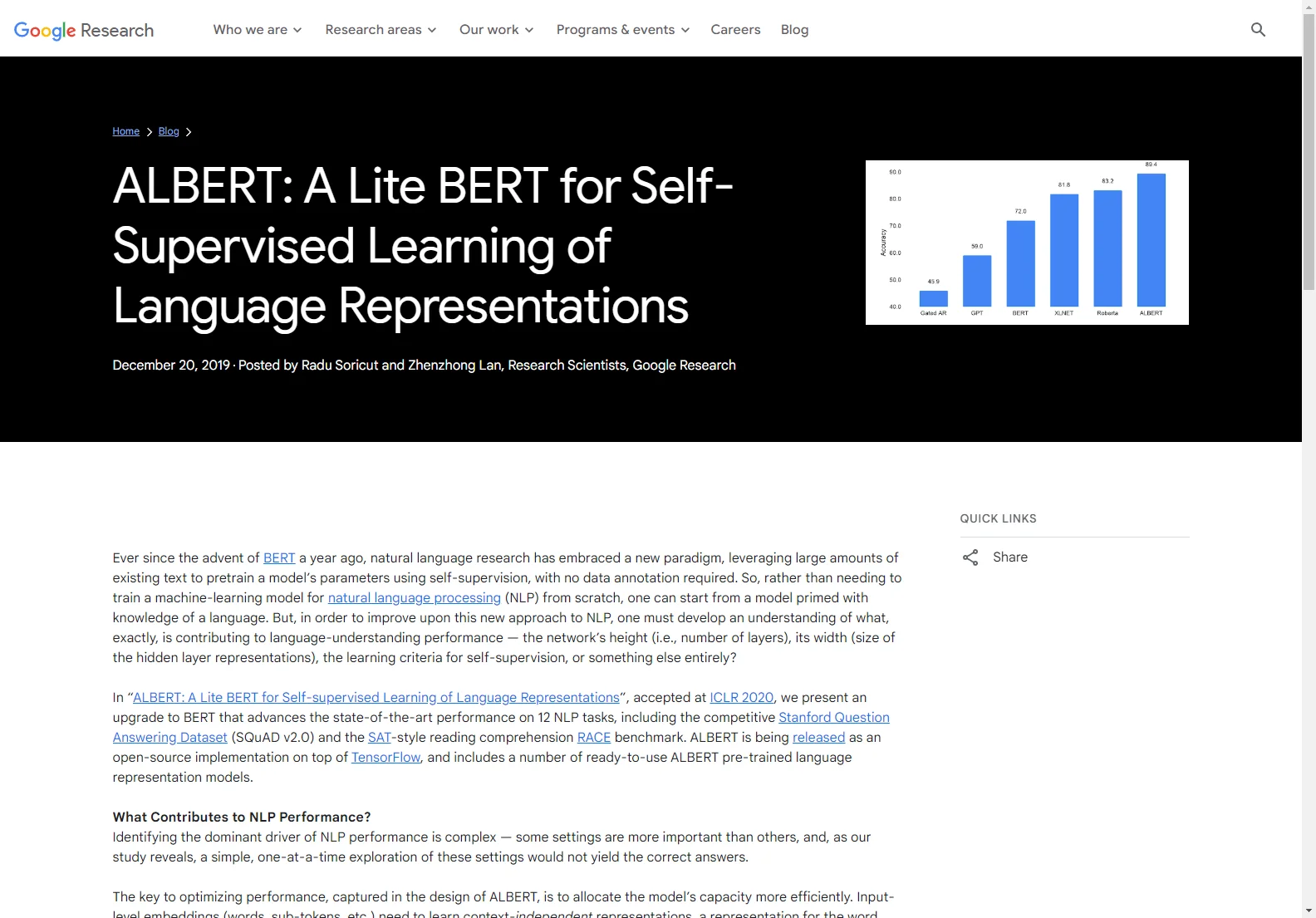
To evaluate the language understanding capability of a model, the RACE dataset is used. ALBERT's performance on this dataset is impressive, especially when trained on a larger dataset, outperforming other approaches and setting a new state-of-the-art score.
The success of ALBERT highlights the importance of identifying and focusing on the aspects of a model that give rise to powerful contextual representations. By doing so, it is possible to improve both the model efficiency and performance on a wide range of NLP tasks.