CM3leon: Revolutionizing Text and Image Generation
In the ever-evolving landscape of AI, CM3leon has emerged as a remarkable generative model. With recent advancements in natural language processing and image generation systems, CM3leon stands out by being capable of both text-to-image and image-to-text generation.
Overview
CM3leon is the first multimodal model trained with a unique recipe. Adapted from text-only language models, it includes a large-scale retrieval-augmented pre-training stage and a multitask supervised fine-tuning stage. This not only results in a strong model but also shows that tokenizer-based transformers can be trained efficiently, even with less compute compared to previous methods.
It achieves state-of-the-art performance for text-to-image generation. For instance, on the widely used image generation benchmark (zero-shot MS-COCO), it attains an FID score of 4.88, outperforming Google's text-to-image model, Parti. This showcases the potential of retrieval augmentation and the impact of scaling strategies on autoregressive models.
Core Features
One of its key features is its versatility. As a causal masked mixed-modal (CM3) model, it can generate sequences of text and images conditioned on other image and text content. This expands the functionality beyond what previous models could do, which were often limited to either text-to-image or image-to-text tasks only.
Large-scale multitask instruction tuning is applied to CM3leon for both image and text generation. This significantly improves its performance on tasks like image caption generation, visual question answering, text-based editing, and conditional image generation.
Basic Usage
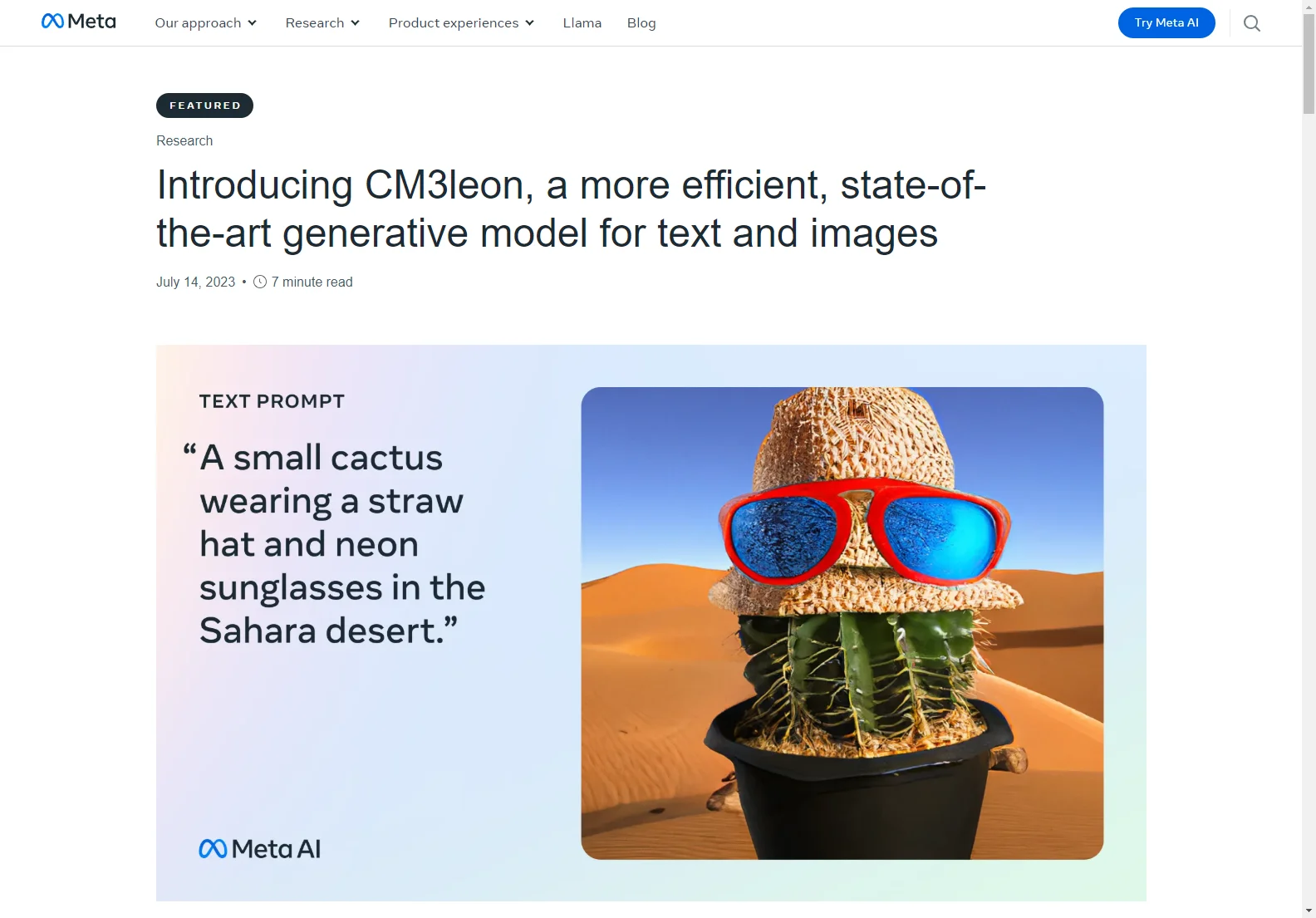
CM3leon can handle various tasks with ease. In text-guided image generation and editing, it excels even when dealing with complex objects or prompts with multiple constraints. For example, it can change the color of the sky in an image as per the text prompt.
In text tasks, it can follow different prompts to generate captions and answer questions about an image. Despite being trained on a relatively smaller dataset of only three billion text tokens, its zero-shot performance compares favorably against larger models on tasks like MS-COCO captioning and VQA2 question answering.
CM3leon's architecture, using a decoder-only transformer, enables it to input and generate both text and images successfully. Its training process, which is retrieval augmented and followed by instruction fine-tuning, contributes to its efficiency and controllability.
In conclusion, CM3leon is a powerful addition to the world of AI, with the potential to boost creativity and find better applications in various domains, especially in the metaverse as we explore the boundaries of multimodal language models.