AudioCraftについて
AudioCraftは、生のオーディオ信号をトレーニングした後、あらゆるジェネレーティブオーディオニーズに対応する単一のコードベースです。このコードベースは、オーディオ生成モデルの全体的な設計を従来のものと比べて簡素化しています。
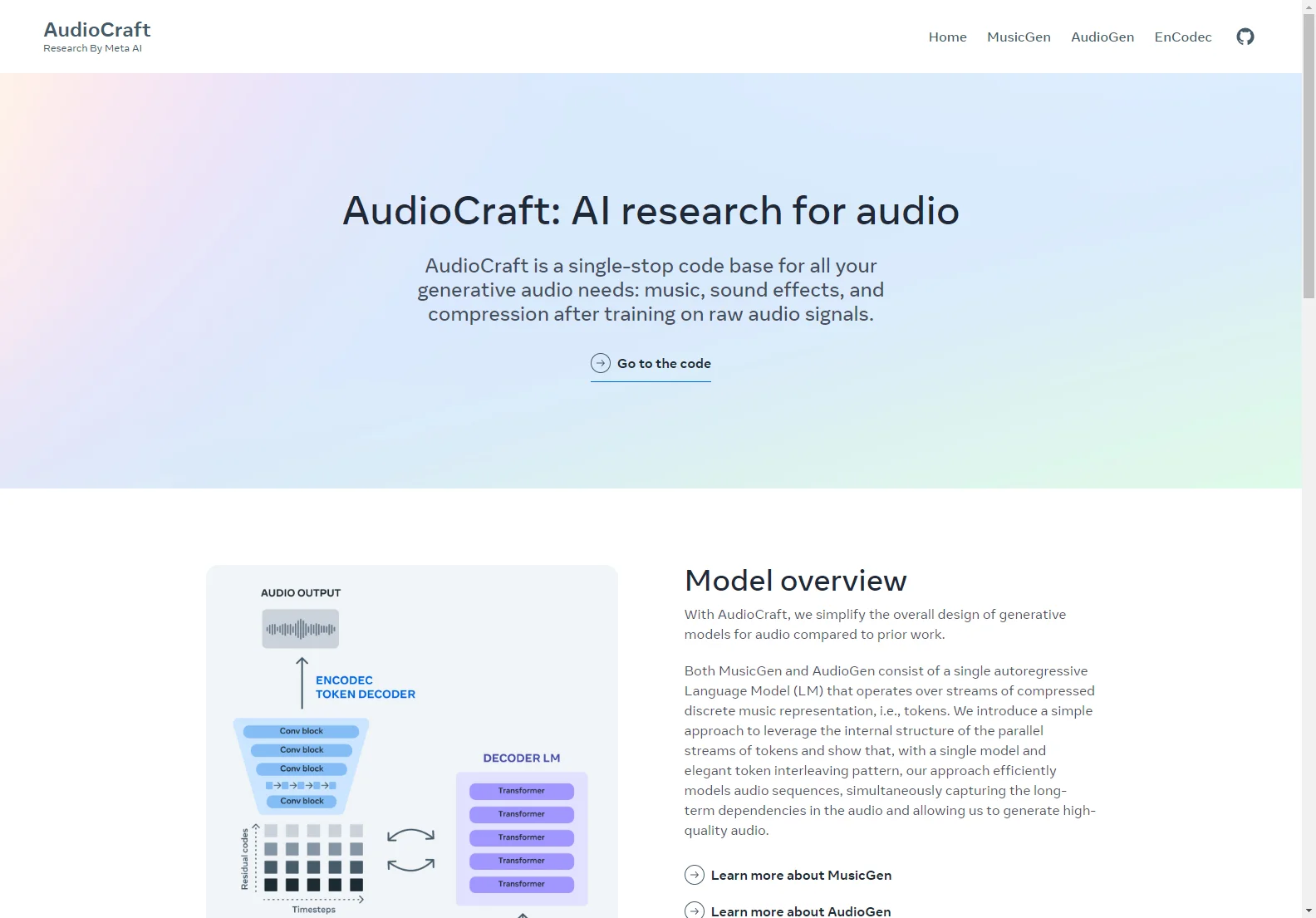
MusicGenとAudioGenは、圧縮された離散的な音楽表現、つまりトークンのストリームに対して動作する単一の自己回帰言語モデル(LM)で構成されています。私たちは、トークンの並列ストリームの内部構造を活用するための簡単なアプローチを導入し、単一のモデルと洗練されたトークンのインターリービングパターンを使用することで、効率的にオーディオシーケンスをモデル化し、オーディオの長期的な依存関係を捉えると同時に、高品質のオーディオを生成できることを示しています。
EnCodecニューラルオーディオコーデックを使用して、生の波形から離散的なオーディオトークンを学習します。EnCodecはオーディオ信号を1つまたは複数の並列ストリームの離散トークンにマッピングします。そして、単一の自己回帰言語モデルを使用して、EnCodecからのオーディオトークンを再帰的にモデル化します。生成されたトークンは、EnCodecデコーダーに供給されて、オーディオ空間にマッピングされ、出力波形が得られます。最後に、テキストエンコーダーを使用してテキストからオーディオへのアプリケーションなど、異なるタイプの条件付けモデルを使用して生成を制御できます。
AudioGenはテキストからサウンドの生成に焦点を当て、環境音からオーディオを生成することを学習しています。サンプルを聴くことができます。MusicGenはユーザーが提供するテキスト入力から多様で長い音楽サンプルを生成します。サンプルを聴くことができます。