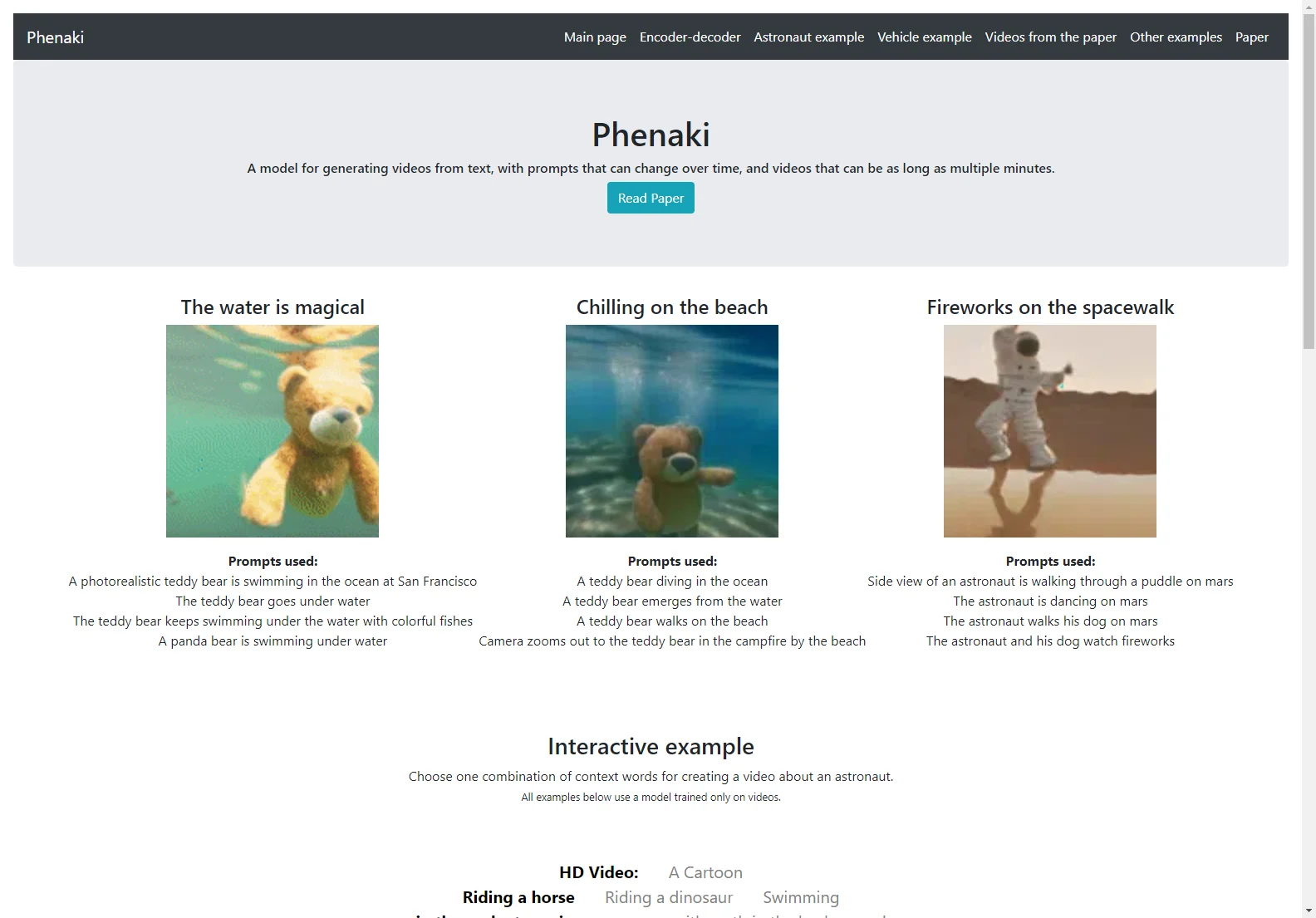
Phenakiについて
Phenakiは、テキストのプロンプトのシーケンスに基づいてリアルなビデオ合成が可能なモデルです。ビデオを生成することは、計算コスト、高品質なテキスト - ビデオデータの限られた量、およびビデオの可変長などの理由から特に困難です。これらの問題に対処するために、ビデオを離散トークンの小さな表現に圧縮する新しい因果モデルが導入されています。このトークナイザーは時間における因果的な注意を使用しており、可変長のビデオで動作できます。テキストからビデオトークンを生成するために、予め計算されたテキストトークンに条件付けられた双方向マスクドトランスフォーマーが使用されています。生成されたビデオトークンはその後、実際のビデオを作成するためにデトークン化されます。データの問題に対処するために、画像 - テキストペアの大規模なコーパスと少数のビデオ - テキストの例の共同訓練が、ビデオデータセットで利用可能なものを超えて一般化できることが示されています。以前のビデオ生成方法と比較して、Phenakiはオープンドメインでの一連のプロンプト(つまり、時間変数のテキストまたはストーリー)に応じて任意の長さのビデオを生成できます。私たちの知る限り、これは時間変数のプロンプトからビデオを生成することを研究する最初の論文です。また、提案されたビデオエンコーダ - デコーダは、時空間の品質とビデオごとのトークン数の点で、現在の文献で使用されているすべてのフレームごとのベースラインを上回ります。
コア機能
- テキストプロンプトに基づいてビデオを生成できます。
- 可変長のビデオに対応できます。
- 高品質のビデオを作成できます。
基本的な使用方法
- テキストプロンプトを入力します。
- モデルがビデオを生成します。
- 生成されたビデオを確認します。