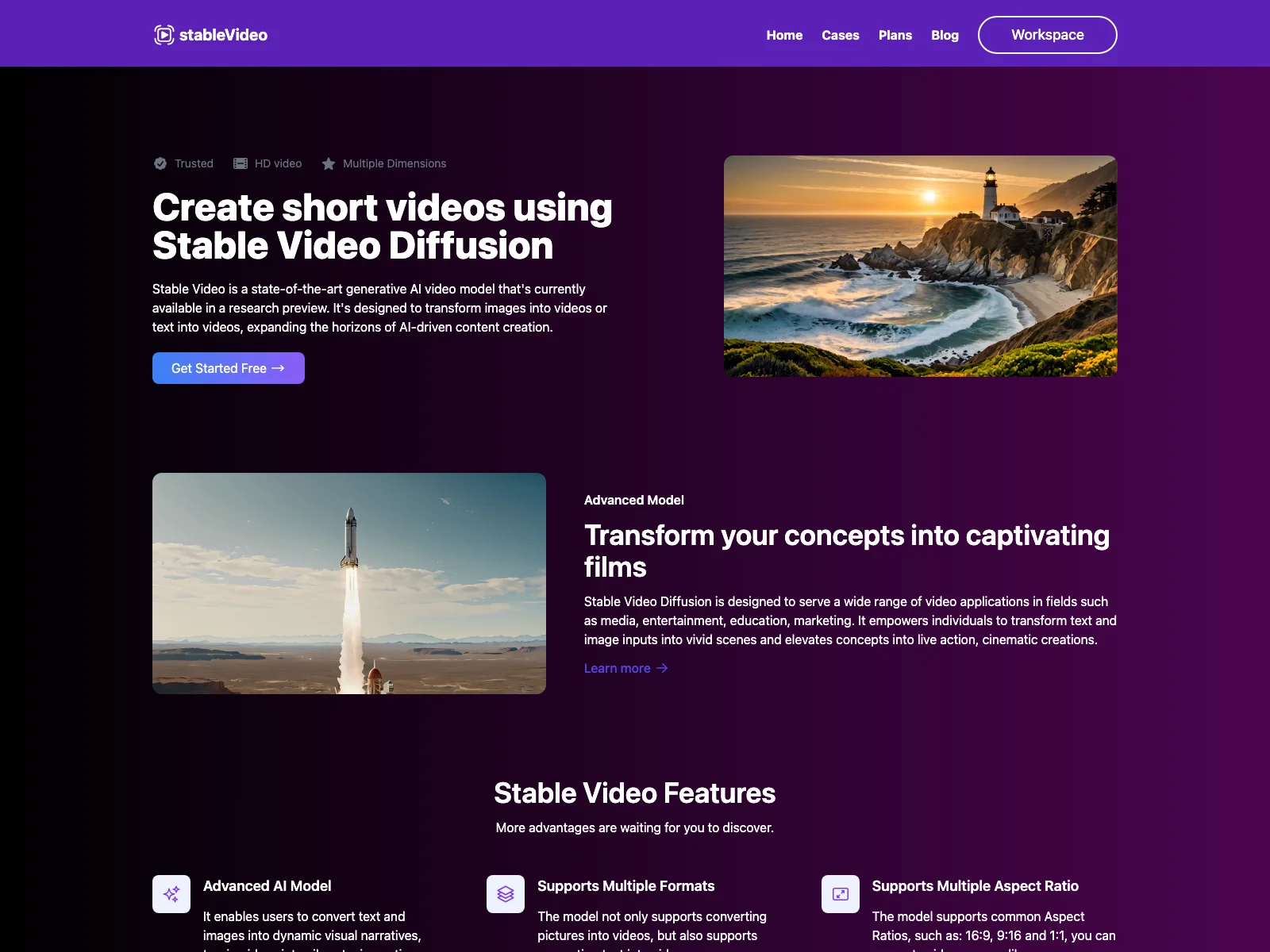
Stable Video Diffusionの詳細
Stable Video Diffusionは現在研究プレビュー版で提供されている、最先端のジェネレーティブAIビデオモデルです。このモデルは画像をビデオに、またはテキストをビデオに変換することができ、AIによるコンテンツ作成の可能性を広げています。
コア機能
- 高度なAIモデル:ユーザーがテキストと画像をダイナミックなビジュアルナラティブに変換でき、アイデアを鮮やかで映画的な体験に変えます。
- 複数のフォーマット対応:画像からビデオへの変換だけでなく、テキストからビデオへの変換もサポートしており、好きなようにビデオを生成できます。
- 複数のアスペクト比対応:16:9、9:16、1:1などの一般的なアスペクト比をサポートしており、自由にビデオを作成できます。
- 高速処理:高速処理サーバーにより、迅速なターンアラウンド時間を実現します。
- ユーザーフレンドリーなインターフェース:初心者と専門家の両方に適した直感的なインターフェースで、ツールの操作が簡単です。
- 柔軟なサブスクリプションプラン:ニーズと予算に合わせて選択できるサブスクリプションオプションが用意されています。
基本的な使用方法 Stable Video Diffusionは、メディア、エンターテインメント、教育、マーケティングなどの分野で幅広いビデオアプリケーションに対応しています。テキストと画像の入力を鮮やかなシーンに変換し、コンセプトをライブアクション、映画的な作品に昇華させることができます。