Stable Diffusion 3 Medium: Revolutionizing Text-to-Image Generation
Stable Diffusion 3 Medium (SD3 Medium), the latest offering from Stability AI, is making waves in the realm of AI-powered text-to-image generation. With a staggering two billion parameters, it stands as a formidable force in this domain.
Overview
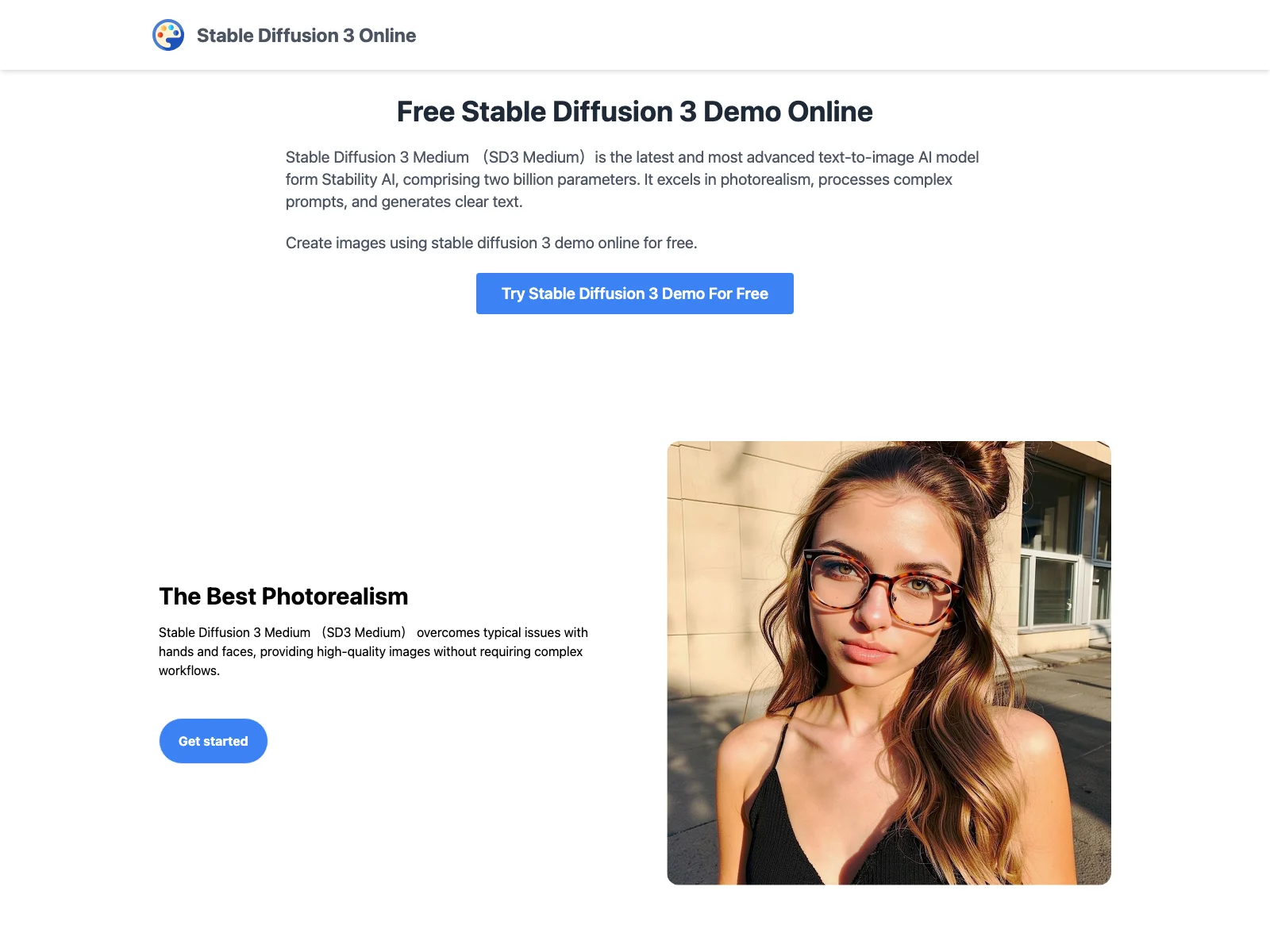
SD3 Medium has been designed to overcome many of the typical challenges faced by previous models. It excels in photorealism, ensuring that the images generated are of top-notch quality. Gone are the days of worrying about issues with hands and faces in the generated visuals; SD3 Medium provides clear and detailed images without the need for complex workflows.
Core Features
One of the standout features of Stable Diffusion 3 Medium is its remarkable prompt adherence. It can comprehend complex prompts that involve spatial relationships, compositional elements, actions, and styles. This means that users can input detailed and intricate descriptions, and the model will do its best to bring those visions to life in the form of stunning images.
Another key aspect is its ability to generate text within the images without artifacting and spelling errors. Thanks to the Diffusion Transformer architecture, it achieves unprecedented results in this regard, adding an extra layer of authenticity to the generated visuals.
Basic Usage
Using Stable Diffusion 3 Medium is a straightforward process. Users can simply input their desired prompts, such as 'A red sofa on top of a white building' or 'A glamorous digital magazine photoshoot, a fashionable model wearing avant-garde clothing, set in a futuristic cyberpunk roof-top environment', and watch as the model works its magic to create corresponding images.
In comparison to other existing AI text-to-image solutions, Stable Diffusion 3 Medium offers a more refined and accurate output. It provides a level of detail and photorealism that sets it apart from the crowd, making it a top choice for those seeking to create captivating and realistic images from text prompts.