More Efficient NLP Model Pre-training with ELECTRA
ELECTRA is a revolutionary pre-training method in the field of natural language processing. It offers a more efficient approach to language pre-training compared to existing techniques.
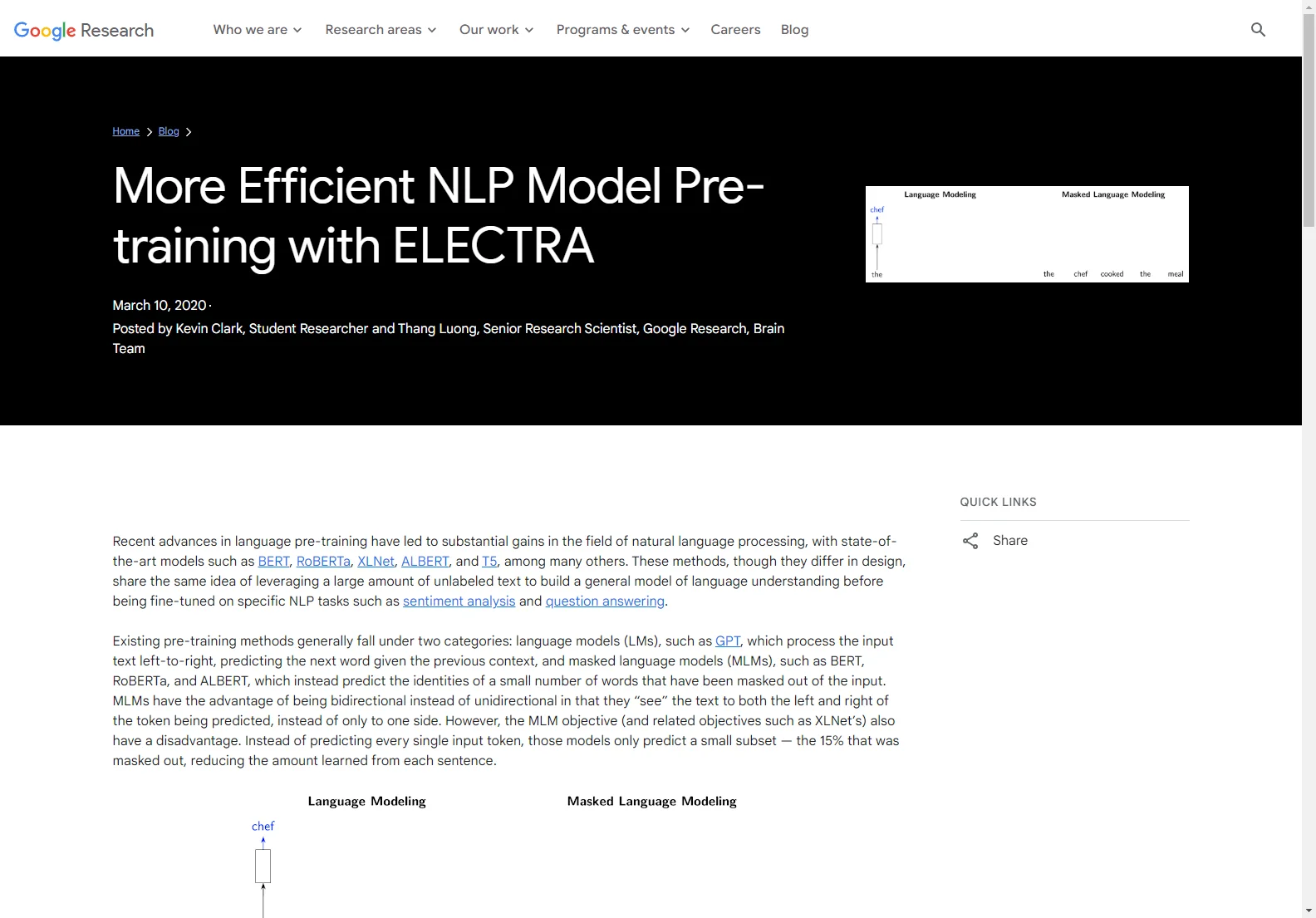
Overview: Recent advancements in language pre-training have led to significant progress in NLP. However, existing methods have their limitations. For instance, language models like GPT are unidirectional, while masked language models like BERT only predict a small subset of masked words.
Core Features: ELECTRA takes a different approach with its replaced token detection (RTD) task. It corrupts the input by replacing some tokens with incorrect but plausible fakes. The model, acting as a discriminator, then determines which tokens have been replaced. This binary classification task is applied to every input token, making it more efficient than traditional methods. Additionally, the generator, a small masked language model, is trained jointly with the discriminator.
Basic Usage: ELECTRA has shown excellent results. It matches the performance of RoBERTa and XLNet on the GLUE benchmark with less compute and achieves state-of-the-art results on the SQuAD benchmark. It works well even at a small scale and can be trained on a single GPU in a few days. The code for pre-training and fine-tuning ELECTRA is available, along with pre-trained weights. Currently, the ELECTRA models are English-only, but there are plans to release multilingual versions in the future.
In conclusion, ELECTRA is a game-changer in the world of NLP, providing more efficient and effective pre-training for a wide range of applications.